Last time we spoke a bit about dynamic programming; specifically about solving Weighted Independent Set on trees. You can read about it here. Today things will get a bit more serious. I’ll start by briefly explaining how the algorithm we sketched for trees extends to graphs of bounded tree-width and then I’ll speak about the thing that makes dynamic programming fast: namely the quotinenting of solution spaces.
This last part is work in progress; feel free to share any feedback in the comments below.
Weighted independent set: from trees to graphs of bounded tree-width.
We already saw how to solve this problem on trees in the previous post in this series. The notation I chose for that post involved structured decompositions which, in case you need a reminder, look like this (see my paper with Zoltan Kocis and Jade Master for the real definition).

I will continue to handwave the definiton of structured decompositions for now since we’ll only use them to talk about tree decompositions.
Don’t worry, I’ll try to make things as general as possible in the next post.
The algorithm I sketched last time for the Maximum Weight Independent set generalized from structured decompositions of trees to structured decompositions of arbitrary graphs. Crucially, the efficiency of the algorithm carries over too: the running time of the algorithm scales exponentially in the size of the largest bag of the decomposition, but it remains linear in the overall input size.
Notation: The maximum bag-size of a strucrtured decomposition of graphs is called the width of the decomposition. In graph theory tree-shaped decompositions are called tree decompositions and the smallest width attainable for constructing a given graph \( G\) with decomposition which is tree-shaped is called its tree-width. It is denoted \(\mathbf{tw}(G)\).
Our algorithm for Weighted Independent Set follows the dynamic programming leitmotif:
- solve your problem on the bags (usually by brute force)
- working bottom-up from the leaves of the tree-shaped decomposition, combine local solutions to get ever-more-global solutions until we find the overall global solution.
For such algorithms to be fast (polynomial time) on some class, we need two things to be true:
- the class has to have bounded width
- we need to quotient the combined solution spaces as we go.
To really understand this last point, let’s look at an example. As before suppose we’re solving Weighted Independent Set. And, for simplicity, suppose we’re solving it on an input grah that admits a path-shaped decomposition \( (P, d)\) of width \( k \) (for some \( k \in \mathbb{N}\)) as in the following example.

Estimating things very roughly, let’s say that any n-vertex graph has at most \( 2^n \) different independent sets. Then, if we were to naïvely solve the independent set problem using the decomposition above, how long would this take?
Well the last step of the compositional algorithm would take time $$2^{|d x_1 +_{d e_{1,2}} d x_2 +_{d e_{2,3}} d x_3 )|} \times 2^{|d x_4|} $$ (I’m dropping parentheses to make things readable… and because I prefer it this way anyway). This is obviously very bad since it’s pretty much exponenetial in the size of the entire input graph.
The key insight we noticed last time is that we don’t need to carry around the entire set \( I_{1,2,3} \) of all independent sets of $$ d(x_1) +_{d(e_{1,2})} d(x_2) +_{d(e_{2,3})} d(x_3). $$ We only need to remember what \( I_{1,2,3} \) looks like locally within \( d(x_3) \). This insight allows us to speed up the algorithm into one running in time \( \sum_{ 1 \leq i \leq 4} f(|d(x_i)|) \) for some exponential function \( f \) which I’m not bothering to estimate right now (from experience, I’d guess it’s probably something like \( f: |d(x_i)| \mapsto 2^{2||d(x_i) |} \), but I haven’t checked this..).
Notice that, if each bag has size bouded above by some constant \( k\), then the runing time of the “quotiented’ version is linear in the input’s overall size!
Another example — this time “by picture”
It’s good to have at least another example on hand. It helps build intutition. So let’s now consider the Longest Path problem.
Longest Path
- Input: a graph G and an integer k.
- Question: does G contain a simple path of length at least k?
How does one solve this problem compositionally?
Well, it’s a standard exercise in paramterized complexity textbooks; indeed it’s so common that it features as one of the first dynamic programming exercises in Flum and Grohe’s textbook.
I’ll sketch the intuitive idea pictorially. Consider the following diagram where we have a path-shaped structured decomposition consisting of three bags \( d(x_1)\), \( d(x_2)\) and \(d(x_3)\) (I’m leaving out the spans so things are easier to see).

Now how can we use the decomposition to solve the Longest Path problem? As John Baez puts it, there is a general trick for gaining intuition:
“as always in mathematics, if you’re trying to figure out how to get something, it’s always good to pretend you already have it and then see what it’s like [so that] you can figure out how to get it.”
Let’s do exactly that. Suppose we are given an optimum solution (a longest path) as drawn in green below.

What does this path look like locally? Well, it’s a disjoint collection of paths (as I’ve highlighted in the second bag of the decomposition below).

This suggets an algorithm:
- enumerate all collections of disjoint paths in each bag (let’s call these local solutions);
- recursively try to join local solutions into larger and larger solutions.
Unruprisingly this algorithm follows the leitmotif we already mentioned.
Now, if you’re getting the hang of how these algorithms go, then your first question should be: “how do we quotient the solution space here?” Well, consider the following diagram.

We have three partial solutions: one in \( d(x_2)\) (drawn in black) and two in \( d(x_1)\) (drawn in green and violet respectively). Here’s the crucial observation: despite the fact that green and violet solutions are different, they link-up to the black solution in the same way. This is important because it means that any extension of the black+green solution (by means of some solution local to \( d(x_3) \) ) is also an extension to the black+violet solution! In other words, from the perspective of answering the Longest path problem the two solutions are almost the same: we can forget the shorter path of the pair (black+green, black+violet).
Try to keep this example in mind. It will be useful for the next section.
Quotienting solution spaces in general
Things will get slightly category-theoretic now, so apologies if you don’t yet speak category-theory (I suggest Emily Riehl‘s book if you want to learn).
Let’s model algorithmic problems \(\mathcal{F}\) on an input graph \( X\) as a poset-valued presehaves; i.e. as functors of the form \( \mathcal{F}: (\mathbf{Sub} X)^{op} \to \mathbf{Pos}\).
For example we could model Independent Set on the input \( X\) as the functor \( \mathcal{I}: (\mathbf{Sub} X) ^{op}\to \mathbf{Pos}\) taking each open
(i.e. a subgraph of \( X\)) to the poset (ordered by inclusion) of all independent sets in \( X’\). On arrows, \( \mathcal{I}\) takes \( X’ \subseteq X”\) to the restriction map \( \mathcal{I}_{X’ \subseteq X”} : \mathcal{I} X” \to \mathcal{I} X’\) taking each independet set \( \iota \in \mathcal{I}X”\) to its restriction \( \iota|_{X’} \in \mathcal{I}X’\) to \( X’\) (this works because the property of being an independent set is closed under taking subgraphs).
It will be convenient to call an independent set \( \iota’\) an extension of \( \iota\) if \( \iota \subseteq \iota’\) is a morphism of a solution space poset \( \mathcal{I}(X’)\) which contains both of these independent sets (where \( X’\) is some subgraph of \( X\)).
We’ll need some notation. Let \( Y \subseteq Y’\) be any two subgraphs of \( X\); we wish to define a functor \( \mathrm{Ext}_Y^{Y’}\) which we’ll refer to as the \( (Y, Y’)\)-extension functor. This will be a contravariant functor \( \mathrm{Ext}_Y^{Y’}: \mathcal{I}Y^{op} \to \mathbf{Sub}\mathcal{I}Y’\) taking
- each object \( \iota \in \mathcal{I}Y\) to the poset (ordered by inclusion) of all those \( \iota’\) in \( \mathcal{I}Y’\) which restrict to \( \iota\); i.e. \( \mathrm{Ext}_Y^{Y’}: \iota \mapsto (\{\iota’ \in Y’ | \mathcal{I}_{X’ \subseteq X”}(\iota’) = \iota\}, \subseteq)\)
- and each morphism \( \iota \subseteq \iota’\) in \( \mathcal{I}Y\) to the restriction $$ \mathrm{Ext}_Y^{Y’}: (\iota \subseteq \iota’) \mapsto \bigl( \mathrm{Ext}_Y^{Y’}( \iota’ ) \to \mathrm{Ext}_Y^{Y’}(\iota) \bigr).$$ To see that this is well-defined, notice that, since \( \iota \subseteq \iota’\), then for all \( \iota”\), if \( \iota” \supseteq \iota’\), then \( \iota” \supseteq \iota\). (In particular this implies that \( \mathrm{Ext}_Y^{Y’}(\iota’)\) is a subposet of \( \mathrm{Ext}_Y^{Y’}(\iota)\).
With this notation, we’re ready to write down how I think “solution space quotienting” should go.
Solution space quotienting
The first two steps are obvious: we compute the solution spaces \( \mathcal{I}(dx)\), \( \mathcal{I}(dy)\), \( \mathcal{I}(de)\) and we use these to compute the joint solution space \( \mathcal{I}(dx +_{de} dy)\) as in the following diagram. (I’m glossing over how this computation is done, but, if you’re interested, then you can check out Section 6 of our paper where we show how to do this step for a fairly large class of problems.)

Now the quotienting starts. So first of all we compute the product

It’s the poset whose objects are pairs \( (\iota_1, \iota_2)\) of elements of the solution space \( \mathcal{I}(d_x)\) and the projections do the obvious thing; namely \( \pi_i: (\iota_1, \iota_2) \mapsto \iota_i\).
Then we take the equalizer of \( \mathrm{Ext}_{dx}^{dx+_{d_e}dy} \circ \pi_1\) and \( \mathrm{Ext}_{dx}^{dx+_{d_e}dy} \circ \pi_2\) as follows.

The poset \( E\) has underlying set $$ \{(\iota_1, \iota_2) \in \mathcal{I}(d_x) \times \mathcal{I}(d_x) | (\mathrm{Ext}_{dx}^{dx+_{d_e}dy} \circ \pi_1)(\iota_1) = (\mathrm{Ext}_{dx}^{dx+_{d_e}dy} \circ \pi_2)(\iota_2)\}$$ consisting of all those local solutions \( \iota_1 \text{ and } \iota_2 \) in $ \mathcal{I}(dx) $ which can be extended in exactly the same way in \( \mathcal{I}(d_y)\).
Compare this to Figure 1 (the one with the green, violet and black paths).
Now, to actually do the quotienting, we compute the coequalizer of \( \pi_1 \varepsilon\) and \( \pi_2 \varepsilon\) as follows.

What does \( P_{x,y}\) look like? It’s what you get when you quotient \( \mathcal{I}(dx)\) by the equivalence relation defined by \( E\); namely the equivalence relation that deems two elements \( \iota_1\) and \( \iota_2\) equivalent if they can be extended by exactly the same solutions in \( \mathcal{I}(dy)\) (i.e. if \( (\iota_1, \iota_2) \in E\)).
The final step is to use this quotient \( P_{xy}\) of \( \mathcal{I}(dx)\) to remove the “spurious” information from \( \mathcal{I}(dx +_{de} dy)\): namely we compute a subposet \( \mathcal{I}_{quot}(dx +_{de} dx)\) of \( \mathcal{I}(dx +_{de} dy)\) consisting of all those \( \iota \in \mathcal{I}(dx +_{de} dy)\) which yield elements in \( P_{xy}\) when restricted to \( dx\).
The idea is that we would then proceed with our computations (as in the naïve algorithm) but using \( \mathcal{I}_{quot}(dx +_{de} dx)\) instead of \( \mathcal{I}(dx +_{de} dy)\) in all future iteration of the algorithms.
So does it work?
Well, I haven’t stated the computational task yet, so the question isn’t a fair one.
Let’s try to see if we get the right kind of objects for a couple of problems.
Sheaves
Recall that I wrote earlier that we could think of our computational problems on graphs as presheaves $$ \mathcal{I}: (\mathbf{Sub}G)^{op} \to \mathbf{Pos}$$. A natural question to ask is whether the quotienting procedure I described above does the right thing when \( \mathcal{I}\) is a sheaf.
Recall that a presheaf \( \mathcal{I}: (\mathbf{Sub}G)^{op} \to \mathbf{Pos}\) is a sheaf if it satisfies the following sheaf condition.
Sheaf condition: suppose we are given a collection of subgraphs \( (G_j)_{j \in J}\) and a collection of sections (i.e. solutions) \( \bigl (s_j \in \mathcal{I}(G_j) \bigr )_{j \in J}\). If they pairwise agree (i.e. \( s_j|_{G_j \cap G_k} = s_k|_{G_j \cap G_k}\) for all \( j,k\) with \( j \neq k\)), then there is a unique section \( s \in \mathcal{I}( \mathrm{colim}_{j \in J}(G_j) )\) restricting to each \( s_j\) (i.e. \( s|_{G_j} = s_j\) for all \( j \in J\)).
So what happens if we apply our construction to \( \mathcal{I}\) when \( \mathcal{I}\) is a sheaf? Well we need to figure out what the equalizer looks like:

As before, it’s underlying set consists of all pairs \( (\iota_1, \iota_2) \in \mathcal{I}(d_x) \times \mathcal{I}(d_x)\) such that $$ (\mathrm{Ext}_{dx}^{dx+_{d_e}dy} \circ \pi_1)(\iota_1) = (\mathrm{Ext}_{dx}^{dx+_{d_e}dy} \circ \pi_2)(\iota_2).$$ Now, since \( \mathcal{I}\) is a sheaf, we immediately have that \( (\iota_1, \iota_2) \in E\) if and only if \( \iota_1|_{de} = \iota_2|_{de}\) (i.e. they agree on the boundary and hence are extendable by the same set of solutions in \( dy\)).
This means that the coequalizer \( (P_{xy}, \rho)\)

will quotient \( \mathcal{I}(dx)\) under the equivalence relation which stipulates that two elements \( \iota_1, \iota_2 \in \mathcal{I}(dx)\) are equivalent whenever they look the same in \( dx \cap dy = de\). In particular this implies that \( \mathcal{I}_{quot}(dx +_{de} dy)\) will be isomorphic to \( \mathcal{I}(dy)\). Thus we’ve just found that the quotinenting was able to “figure out” that solving a “sheaf problem” amounts to filtering partial solutions!
Note that, by what we’ve just observed, we have obtained linear FPT-time algorithms for any sheaf-problem parameterized by the maximum size of a bag in a tree-shaped structured decomposition on graphs.
In of itself, since we stated it only for graphs, the result above is nothing new: after all it is already known that such problems are in FPT parameterized by tree-width.
However, it is easy to see that our result should generalize to any category and sheaf-problem (provided appropriate obvious computability conditions are satisfied by the category and sheaf in question).
So what can we encode as sheaves? Well, for starters, we can encode our favourite problem so far, the Max Independent Set problem! Furthermore, we can also encode the H-coloring problem which is defined as follows.
H-coloring
Input: we’re given graphs G and H
Question: is there a homomorphism from G to H?
When your presheaf ain’t a sheaf
We’ve seen that sheaves are particularly nice problems. However, it seems unlikely to me (despite being a “sheaf-novice”) that all computational problems should yield a sheaf. Examples of presheaves which fail to yield sheaves under the subobject topology include the Max Planar Subgraph and Longest Path presheaves.
Since we already mentioned Longest Path in this post, let’s stick with it and forget about Max Planar Subgraph for now.
A natural question is to ask: does the quotienting idea I presented above yield something useful for the Longest Path presheaf?
For starters, let’s define this presheaf; I’ll call it $ \mathcal{L}: (\mathbf{Sub} G)^{op} \to \mathbf{Pos}.$$ It takes each subgraph of G to the set of all collections of disjoint paths in that subgraph (see the diagrams earlier inthis post if you want something pictorial to stare at). On arrows \( \mathcal{L}\) takes subgraphs \( G” \subseteq G’ \subseteq G\) of \( G\)to the obvious restriction of path-forests in \( G”\) to path-forests in \( G’\).
Now, if you work-out what the quotienting does, you’ll find that \( \mathcal{L}_{quot}(d{x_1} +_{de_{12}} d{x_2})\) sees the black+green and black+violet solutions below as equivalent.
The only issue is that the chosen representative for the equivalence class containing black+green and black+violet need not be the longest one.
This seems like a relatively easy issue to fix, so I’ll leave it as future work for myself. What is more pressing is determining whether the resulting quotiented solution space is small enough for fast dynamic programming.
To that end, I’ll cheat a little and use combinatorics. How big can \( \mathcal{L}_{quot}(dx_1 +_{1,2} dx_2 +_{2,3} \dots +_{k-1,k} dx_k)\) be? Well, let’s ask how many non-isomorphic solutions there can be in the coequalizer \( P_{1,2,\dots,k}\). After staring at it a bit, you’ll find that \( |P_{1,2,\dots,k-1}| \leq 2^{|d_{k-1,k}| \choose 2} \) (where \( d_{k-1,k}\) is the base of the span from the (k-1)-th bag to the k-th bag). To see this notice that two solutions of \( \mathcal{L}(dx_1 +_{1,2} dx_2 +_{2,3} \dots +_{k-2,k-1} dx_{k-1})\) are identified in \( P_{1,2,\dots,k-1}\) when they contract to the same thing in \( d_{k-1,k}\). The number of these contractions is at most \( 2^{|d_{k-1,k}| \choose 2}\) (think of it as choosing to add an edge between a pair of vertices in \( d_{k-1,k}\) if contracting some path to the left — i.e. a path in \( P_{1,2,\dots,k-1}\) — identifies these vertices). This is great news since it means that our quotienting once again yields an FPT-time algorithm 🙂
Until Next time
A few notes on future work (ther are undoubtedly lots of directions I’ll forget to mention).
- In the next post I’ll try to generalize the quotienting approach I’ve sketched here and lift it from graphs to other categories.
- There is also some work to be done on how to ensure that we choose a “best” representative of the quotiented solution space.
- The efficiency of the algorithm for sheaves was easy to show; however, for the Longest Path example, I resorted to some simple combinatorial estimation. Although it does the jobin this instance, this appraoch does not generalize, so more thought is needed on what properties can be imposed on the presheaves that define our problems that allow us to deduce upper-bound estimates (in terms of monomorphisms of solution spaces) on the size of the quotinented solution space.
- There are a lot of \((-)^{op}\)-s floating around. This is entirely because \( \mathrm{Ext}\) is contravariant. It would be nice to avoid this somehow..
If you are perplexed or have any ideas/thoughts/reflections, please let me know in the comments (or otherwise).
Ciao!
 of some input vertex-weighted tree
of some input vertex-weighted tree  which has maximum weight such that that no two vertices of
which has maximum weight such that that no two vertices of  .
. 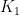 (the 1-vertex complete graph; I’ll abbreviate it simply as “
(the 1-vertex complete graph; I’ll abbreviate it simply as “ “). In category theory this is called a pushout; I’ll adopt this notation here: pick two vertices of two trees
“). In category theory this is called a pushout; I’ll adopt this notation here: pick two vertices of two trees 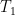 and
and 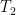 — by choosing homomorphisms
— by choosing homomorphisms  — then the pushout of this diagram is the tree
— then the pushout of this diagram is the tree 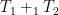 obtained by “gluing” the image of
obtained by “gluing” the image of  and suppose further that we already computed all of the independent sets in
and suppose further that we already computed all of the independent sets in 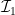 and
and  –, then we observe that we can compute all of the independent sets in
–, then we observe that we can compute all of the independent sets in  and
and  in
in 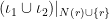 is an independent set in the closed neighborhood of
is an independent set in the closed neighborhood of 
 ).
).  of graphs and graph homomorphisms. A structured decomposition of graphs (which I’ll simply refer to as a “decomposition” in this post) is any diagram in
of graphs and graph homomorphisms. A structured decomposition of graphs (which I’ll simply refer to as a “decomposition” in this post) is any diagram in 
 as the label of the vertex
as the label of the vertex  . Each edge of the shape is labeled by a span (a generalized relation) of graphs: for example the edge
. Each edge of the shape is labeled by a span (a generalized relation) of graphs: for example the edge  is labeled by the span
is labeled by the span  consisting of two graph homomorphisms
consisting of two graph homomorphisms 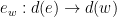 and
and 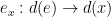 .
. 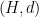 of shape
of shape  , then I can build a graph out of this recipie: for each edge
, then I can build a graph out of this recipie: for each edge  of
of 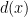 to the bag
to the bag  along the image of
along the image of 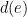 . In other words I take a bunch of pushouts. Here’s an example of a graph (left hand side) built as a gluing (colimit) of a tree-shaped structured decomposition (right hand side):
. In other words I take a bunch of pushouts. Here’s an example of a graph (left hand side) built as a gluing (colimit) of a tree-shaped structured decomposition (right hand side):


 of the input tree
of the input tree  . This edge partitions
. This edge partitions 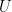 into two trees
into two trees 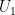 and
and 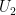 (containing
(containing  and
and  respectively) and in so doing it also partitions
respectively) and in so doing it also partitions 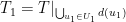 and
and 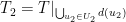 .
. 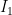 be the set of all pairs
be the set of all pairs 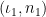 where
where  and
and  is the maximum weight of an independent set in
is the maximum weight of an independent set in 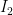 be defined similarly, but for
be defined similarly, but for  and
and 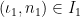 and
and  , conclude that there is an independent set of weight
, conclude that there is an independent set of weight  in
in 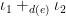 is an independent set in the graph
is an independent set in the graph 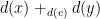 .
. .
. 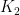 . So here’s a quiz:
. So here’s a quiz: